Local AI on the Edge: What Running Models on Your Own Hardware Actually Looks Like in 2026 — and Where It Still Falls Apart
The hardware finally caught up. Here's the honest capability ceiling nobody's marketing.

The Moment the Conversation Shifted
Picture this: you've been paying per-token to a cloud API every time you summarise a document or autocomplete a block of code. Then someone tells you the same model — or something close enough — can now run entirely on the laptop already sitting on your desk, with no network call, no subscription, no data leaving your machine. That's not a forum fantasy anymore. It's what pushed the 'local AI needs to be the norm' conversation to a genuine tipping point in 2025 and 2026. Two years ago, if you wanted to work with a GPT-4-class language model, you had exactly one option: send your data to someone else's server and pay by the token. According to SitePoint's 2026 guide to local LLMs, that constraint has now 'evaporated.' Open-weight models have reached performance parity with the best cloud offerings, and consumer hardware has crossed a threshold where running them locally is 'not just feasible but, for a growing number of developers and organizations, the preferred default.' But 'local AI' is doing a lot of work in that sentence. What it actually means in practice depends almost entirely on which task you're asking it to do — and how much RAM your machine has.

What the M4 MacBook Pro 24GB Actually Runs — and What It Doesn't
The M4 MacBook Pro with 24GB unified memory is the machine most people in this conversation are pointing at as the concrete test case. It's the baseline for 'serious but not exotic' local inference. So what's the real picture? Apple Silicon's key architectural advantage is unified memory: the CPU and GPU share the same pool, so a model doesn't need to fit into a separate, dedicated VRAM slice the way it does on a Windows PC with an NVIDIA GPU. On an M3 Max with 128GB of unified memory, a 70B parameter model can run on a single device — something that requires a dual-GPU setup on the NVIDIA side. That matters because 70B models produce noticeably better output quality than their smaller siblings on most reasoning and writing tasks. But 24GB is not 128GB. At that memory ceiling, you are running quantised models — compressed versions of the originals that trade some output quality for a smaller footprint. Apple's MLX framework supports quantisation natively: a 7B Mistral model can be converted to 4-bit in seconds using a single command. The 7B to 13B range at 4-bit quantisation is the sweet spot for 24GB machines. Inference speed on Apple Silicon for that range sits at 25–50 tokens per second depending on the chip — readable in real time, but not instant. A comparable NVIDIA RTX 4090 hits 80–140 tokens per second for the same model sizes, making it 2–4x faster for models that fit within its 24GB VRAM.
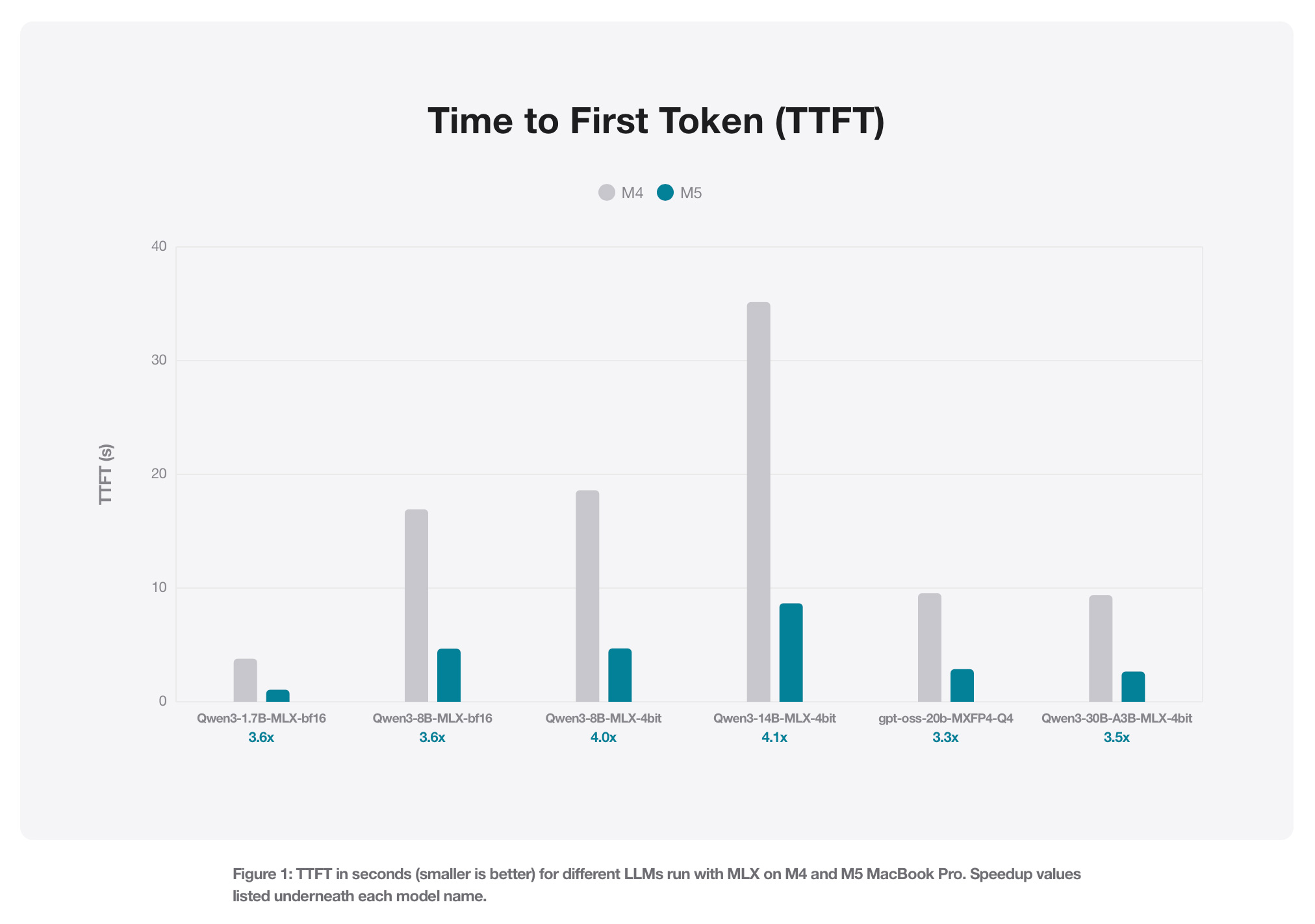
Not All 'Local AI' Is the Same Task — The Hardware Profile Changes Completely
Here's what the marketing materials don't say clearly enough: coding assistance, document summarisation, and image generation have almost nothing in common when it comes to hardware requirements. For **coding assistance**, a well-quantised 7B or 13B model on a 24GB machine produces genuinely useful autocomplete and code review. The latency is low enough that it feels interactive. This is the use case where local inference earns its keep most reliably for a non-engineer power user. For **document summarisation**, context window size becomes the constraint, not raw speed. Consumer hardware running quantised models faces context window limits that can truncate long documents mid-processing. If you're summarising a short brief, fine. If you're processing a 200-page contract, you'll hit the ceiling. For **image generation**, the model architecture is entirely different — and the gap between local and cloud widens sharply. MLX supports image generation, but multi-modal on-device capability does not reach parity with cloud offerings on consumer hardware in 2026. The compute profile for diffusion models strains a 24GB unified memory machine in ways that text generation does not. The M5 Pro and M5 Max — Apple's newest chips, released March 2026 — change the ceiling significantly. The M5 Max supports up to 128GB of unified memory and delivers up to 4x AI performance compared to the previous generation, with Neural Accelerators built into each GPU core. Apple's own benchmarks showed the M5 delivering a 19–27% improvement in generation speed over the M4 for token throughput across models including Qwen 8B and 14B at 4-bit quantisation.

The Honest Failure Modes: Quantisation Loss, Context Limits, and the Multi-Modal Gap
Quantisation is the local AI story's most under-discussed trade-off. Compressing a model from its native 16-bit or 32-bit precision down to 4-bit reduces memory footprint dramatically — but it is not lossless. The output quality gap between a full-precision 70B model and a 4-bit quantised 13B model is real, even if benchmarks don't always surface it cleanly. For casual summarisation it's tolerable. For legal document review or nuanced code generation in an unfamiliar framework, the degradation can matter. Context window limits on consumer hardware are the second failure mode. Running a large context — feeding the model an entire codebase or a long conversation history — requires keeping that context in memory alongside the model weights. On a 24GB machine, this creates a genuine ceiling on what tasks are feasible in a single pass. The third failure mode is multi-modal parity. Cloud models from the major providers handle image understanding, voice, and combined text-image tasks at a level that local on-device inference cannot currently match on consumer hardware. The M5's Neural Accelerators improve inference speed meaningfully, but they do not close the multi-modal capability gap with frontier cloud models. The NVIDIA RTX 4090 is faster at pure text token generation for models that fit in its 24GB VRAM — 80–140 tokens per second versus Apple Silicon's 25–50 — but its 24GB hard VRAM ceiling means 70B models require layer offloading to system RAM, which slows things down significantly. The M3 Max at 128GB beats the RTX 4090 on 70B inference: roughly 14 tokens per second versus approximately 8 tokens per second with layer offload.

The Privacy Argument: Real, but Overstated for Most Users
The privacy case for local inference is genuine but frequently overclaimed. Running models locally eliminates the data-leaving-your-machine problem entirely — no network round-trip, no API logs, no third-party data retention. For specific use cases this is a hard requirement: a lawyer reviewing privileged client documents, a developer working on proprietary source code under NDA, a healthcare researcher handling patient data. For those users, local inference is not ideological — it's compliance. For everyone else, the honest question is whether the privacy gain is worth the capability and convenience trade-off. The cloud APIs being replaced are running models that are, in most cases, still ahead of what fits on a 24GB consumer machine at acceptable quality. Paying by the token to a major provider is not meaningfully riskier for the average user writing marketing copy or summarising meeting notes than using any other cloud software service. The cost argument is more durable than the privacy argument for most users. Eliminating recurring API costs is a real financial benefit for developers running high query volumes. The latency argument — no network round-trip — is also real, though SitePoint notes that 'first-token generation latency depends on hardware,' meaning a slow machine can introduce its own latency that offsets the network saving. The honest summary: local inference is worth the friction for privacy-sensitive professional use cases and for cost-conscious high-volume developers. For everyone else, the motivation is often ideological — which is a legitimate reason to do something, but should be named accurately.
What to Watch Next
Three developments will determine how quickly the capability ceiling moves. First, the M5 Pro and M5 Max represent a meaningful generational step, not an incremental one. Apple's new Fusion Architecture — combining two dies into a single SoC for the first time — delivers up to 4x AI performance compared to M4, with memory bandwidth on the M5 Max reaching 614GB/s. Higher bandwidth directly improves inference speed for large models. The M5 Pro starts with 24GB unified memory and is configurable up to 64GB; the M5 Max goes up to 128GB. The 64GB M5 Pro tier is the one to watch for the 'serious local inference without exotic hardware' use case. Second, quantisation quality is improving. The gap between a quantised model and its full-precision counterpart is narrowing as techniques improve. Apple's MLX supports MXFP4 precision natively on M5, as evidenced by Apple's own benchmarks using GPT OSS 20B in native MXFP4 — a format that extracts better quality per bit than earlier quantisation approaches. Third, the software tooling is maturing fast. Ollama, LM Studio, and MLX LM have made model download and deployment genuinely accessible to non-engineers in 2026. The bottleneck is no longer setup complexity — it's hardware memory and knowing which model size actually fits your use case. That clarity is what the conversation has been building toward.

Sources
- [1]Local LLM Hardware Requirements: Mac vs PC 2026 — SitePoint
- [2]Exploring LLMs with MLX and the Neural Accelerators in the M5 GPU — Apple Machine Learning Research
- [3]Mac M3 Max vs RTX 4090: Local LLM Performance Showdown 2026 — SitePoint
- [4]Apple shows how much faster the M5 runs local LLMs on MLX — 9to5Mac
- [5]MacBook Pro M5 Pro / M5 Max UAE Price from Dhs 9,299 | Full Specs — Tbreak Media
- [6]Apple introduces MacBook Pro with all-new M5 Pro and M5 Max — Apple
- [7]The Definitive Guide to Local LLMs in 2026: Privacy, Tools, & Hardware — SitePoint
- [8]The best MacBook for programming: Don't waste your time and money on the wrong MacBook — Creative Bloq
Comments
No comments yet — be the first to weigh in.